


Understanding SQD.AI's Data Lakehouse
why the protocol is mission critical infrastructure for DeAI & DePIN


To fully appreciate SQD.AI’s evolution from blockchain indexer to Web3 data lakehouse, it’s important to first understand the nuances of data management infrastructure and what they each offer Web3 applications.
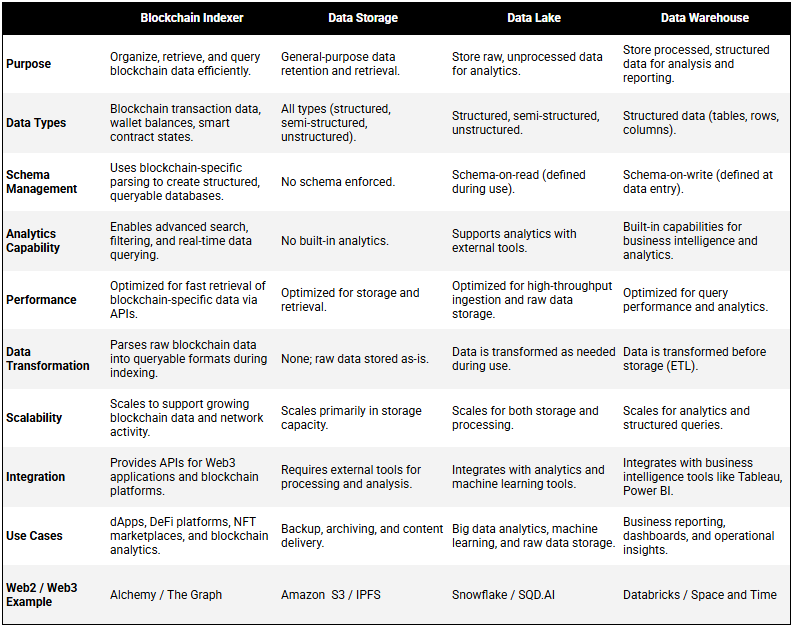
Blockchain Indexers (e.g. The Graph)

Blockchain indexers are platforms that organize, retrieve, and query blockchain data. By parsing blocks and extracting data such as transactions, wallet balances, and event logs, indexers create structured, searchable databases that can be queried via APIs. This capability is essential for Web3 applications, enabling real-time updates, advanced search features, and user-specific data retrieval for use cases like DeFi analytics or NFT marketplaces.
While indexers were key enablers of the DeFi 1.0 revolution in 2019, most are limited in scope, scale, and virtual machine diversity, and therefore cannot fulfill the complex data management demands of today’s Web3 AI & DePIN projects.
Data Storage (e.g. IPFS)
Data storage serves as a general-purpose solution designed to retain and retrieve data in various formats, including structured, semi-structured, and unstructured data. It is primarily used for basic tasks like archiving, backups, and straightforward data access rather than for advanced analytics. These systems do not enforce any specific schema, allowing data to remain in its raw or near-raw format, such as images, videos, and text files.
Optimized for capacity and durability, data storage systems are built to scale massively, making them suitable for storing petabytes of data. However, they lack the computational performance necessary for analytics and complex data processing. They are typically cost-effective, with pricing based on storage volume and retrieval requests, making them ideal for simple use cases like storing raw log files, media assets, or backups, rather than dynamically interacting with applications in real-time.
Data Lakes & Warehouses (e.g. Snowflake)
Data lakes & warehouses can be thought of as blockchain indexers on steroids, ones that can store and query both on and offchain data, which is essential functionality for AI and DePIN applications that are powered by diverse, proprietary datasets (more on this later).

A data lake is designed to store raw, unprocessed data in its native format. It is built to handle structured, semi-structured, and unstructured data, enabling advanced analytics and big data processing. Data lakes use a schema-on-read approach, where data is structured only when accessed for specific purposes. This flexibility makes them ideal for storing diverse datasets, including IoT data, log files, and multimedia.
Data lakes are optimized to support analytics and machine learning use cases, often integrating with cloud-based analytics platforms. They are highly scalable, designed to manage large volumes of diverse data efficiently, and are cost-effective for storage.
A data warehouse is a specialized system designed for storing and analyzing structured data. These systems are optimized for business intelligence and analytics, supporting use cases like reporting dashboards, predictive analytics, and decision-making. Data warehouses enforce a schema-on-write model, where data is structured at the time of ingestion. This structured approach allows for high-performance query optimization and seamless integration with business intelligence tools.
Data warehouses are built for scalability, allowing organizations to manage large workloads through horizontal or vertical scaling. However, they are typically more expensive due to the specialized infrastructure and computational power required for analytics. These systems excel in extracting insights from processed data, making them invaluable for tasks such as analyzing customer purchasing trends or forecasting sales.
Data Lakehouse (e.g. SQD.AI)
The data lakehouse, SQD.AI’s ultimate vision, is a modern hybrid approach that merges the flexibility and scalability of data lakes with the high-performance analytics and governance of data warehouses. It’s designed to handle both raw and processed data in a single system, eliminating the need for separate data silos. This functionality is ideal for complex Web3 applications that need to interact with a diverse set of on and offchain data in real-time, which is especially relevant in Web3 AI (where data is the differentiator) and DePIN (where data is the product).

Why Not Just Use Snowflake?
Snowflake is a highly successful Web2 data lakehouse, boasting a $60B valuation, billions in annual revenue, and an impressive list of enterprise customers, such as Adobe, Citibank, ExxonMobil, Cisco, Pfizer, and AT&T. So why can’t Web3 projects just use Snowflake?

AI & smart contract consumption: Web2 products, like Snowflake, require permission from and trust in the vendor. Conversely, Web3 applications require data infrastructure solutions that are permissionless and trustless - these characteristics permit decentralized agents and/or smart contracts to access data resources directly without compromising the security of the rest of the stack. This allows optimal design flexibility, so agents can seamlessly identify and access the best data for each independent action.
Single point of failure: My last post explained the fundamental design flaw of centralized data networks, which has continuously enabled bad actors to steal sensitive information. Unsurprisingly, Snowflake had a massive data breach last year, resulting in the theft of hundreds of millions of user records from enterprise customers such as Santander Bank and Ticketmaster.
Bottom line: if one part of the tech stack, such as a data lakehouse, is centralized, the entire stack is centralized.
SQD.AI: Mission Critical for Web3 AI
AI agents have become the first Web3 AI category to find PMF, but most run (almost) completely on centralized and/or unverifiable infrastructure. These agents will continue to be limited in functionality until they achieve Web3 compliance: full-stack decentralization & verifiability. Can you really give autonomous agents access to your financial assets and/or sensitive personal information without proof they're being used appropriately and securely? Of course not! Without Web3 compliance, AI agents will remain glorified chatbots with little utility, i.e. memes.
To operate onchain, Web3 AI agents of course require permissionless and trustless access to blockchain data. This is fairly well understood by the market (and offered by SQD.AI today) but only represents one piece of the puzzle. As LLMs continue to commoditize, agent differentiation & value will mostly depend on the system’s proprietary data, including accumulated onchain behavioral interactions (episodic memory) and offchain knowledge bases (semantic memory).

Storing and managing this data requires a diverse and scalable data management platform. For decentralized agents, SQD.AI’s lakehouse is uniquely positioned to offer this functionality in a Web3-compliant manner.
SQD.AI: Mission Critical for DePIN
The novelty of DePIN is its permissionless and trustless access to resources, such as connectivity networks or data, so they can be consumed by automated smart contracts and/or autonomous AI agents (although to-date these resources have mostly been consumed by humans). By tokenizing access to these resources, the Web3 design space for compute, data, and connectivity legos grows exponentially.
DePINs that collect & tokenize various data (GPS, mapping, web scraping, weather, traffic, etc.) require a highly scalable and Web3-compliant way to store, manage, and monetize these diverse datasets, which will continue to become more valuable as AI progresses onchain. In order to unlock the true value of DePINs, monetizing tokenized access to resources, these networks will need to leverage SQD.AI’s data lakehouse to manage data monetization operations.
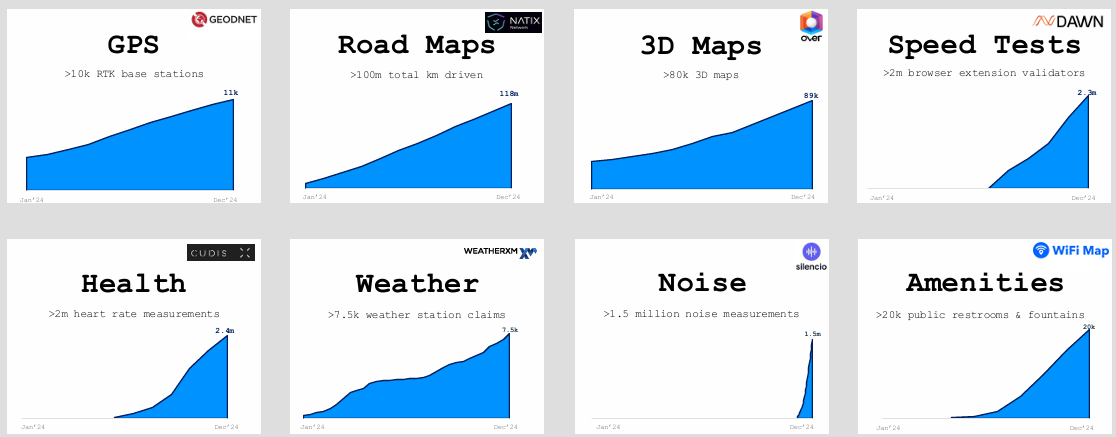
SQD.AI: Solving Web3-Compliant Data Scalability
In Web2, data lakehouses have become some of the most important and valuable companies in the tech-stack. Snowflake and Databricks have both achieved $60B+ valuations in a relatively short period of time and will only continue to grow in power as AI proliferates throughout the economy. Creating a Web3-compliant Snowflake or Databricks is no simple task, but the team at SQD.AI has been working towards this vision for the past four years. Since day one, each technical and architectural decision was based on optimizing scalability, efficiency, and flexibility, with the vision to expand from blockchain indexing into something much larger and more exciting: a web3-compliant data lakehouse.
SQD.AI’s Differentiated Technical Design
(from our original SQD thesis)
SQD.AI’s unique approach to modular and customizable data processing, combined with its focus on flexibility, performance, and scalability, sets it apart from other Web3 data management platforms. We believe this functionality will become increasingly valuable as the industry matures and applications become increasingly more multi-chain and complex.
Customizable Indexers and Processors
Flexible Indexing: SQD.AI allows developers to build highly customizable indexers and processors, which can be tailored to specific use cases. This flexibility makes it easier to handle complex data integration tasks and extract meaningful insights from blockchain and other data.
Performance Optimization: Custom processors can be optimized for performance, ensuring that indexing and querying are efficient and scalable.
Multi-Stage Processing Pipeline
Data Flow Architecture: SQD.AI employs a multi-stage processing pipeline that separates data extraction, transformation, and storage into distinct stages. This architecture improves the manageability and scalability of data processing tasks.
Modularity: Each stage of the pipeline can be independently developed and optimized, providing greater control over the data processing workflow.
Support for Multiple Data Sources
Diverse Blockchain Integration: SQD.AI supports most virtual machine environments and can integrate with various databases, making it a versatile tool for developers working across different blockchain ecosystems.
Adaptability: The platform's ability to handle multiple data sources ensures it can adapt to the evolving needs of the blockchain industry.
Developer-Friendly Tools and SDKs
Comprehensive SDK: SQD.AI offers a Software Development Kit (SDK) that includes tools and libraries to simplify the development of custom data indexers and processors.
API Support: The platform supports various APIs for querying data, including GraphQL and SQL, providing flexibility for developers in how they access and use the data.
Decentralized and Scalable Architecture
Decentralized Processing: SQD.AI leverages a decentralized network of nodes to process and index data, ensuring high availability and fault tolerance, and its verifiability allows direct integration with onchain smart contracts (database coprocessor).
Scalability: The platform is designed to scale horizontally, allowing it to handle increasing amounts of data and growing numbers of queries efficiently.
Performance and Efficiency
High Performance: By allowing custom optimizations at various stages of the data processing pipeline, SQD.AI can achieve high performance in data indexing and querying tasks.
Efficient Resource Use: The platform's architecture ensures the most efficient use of computational resources, reducing the cost and complexity of data processing.
The last point is especially important when comparing SQD.AI to The Graph, which has highly inefficient network operations and unsustainable economics. As illustrated below, although the protocol is relatively mature, token incentives still grossly exceed network revenue by 50x-100x each month:

Architecturally, The Graph's “monolithic” indexing node is a black box that executes subgraphs compiled into WASM. The data is sourced directly from the archival node and local IPFS, and the processed data is stored in a built-in Postgres database. In contrast, SQD.AI offers near zero-cost data access, more granular data retrieval from multiple blocks, and superior batching and filtering capabilities.

Call to Action
The team is currently working 24/7 to showcase new use cases for the data lakehouse. If your project is building in the Web3 AI or DePIN sectors, and you want to learn how SQD.AI can enhance and differentiate your product, please DM me on twitter: @atterx_
About M31 Capital
M31 Capital is a global investment firm dedicated to crypto assets and blockchain technologies that support individual sovereignty.
Website: https://www.m31.capital/
Twitter: https://twitter.com/M31Capital